SHA1加密算法
SHA1 算法和 MD5 总体上很类似,算法流程也差不多
原始数据准备
还是以"password"这个字符串的数据为例
转换成十六进制就是: 70 61 73 73 77 6f 72 64,长度 8 个字节,64 位
接下来开始填充,先补一个 1,再补 k 个 0,使得消息满足 ()64+1+k) = 448
64+1+k = 448 即 k=383,需要补一个 1 和 383 个 0
最后 64 位用来表示原始数据的长度,原始数据长度为 8 个字节,64 位,用 0x0000000000000040(16 进制,大端序)SHA-1 使用大端序,所以这 8 个字节直接按照顺序附加
填充完成,如下所示:
消息扩展
这里是另一个与 MD5 不同的地方
目标:将一个 512 位,16 个 32 位(字)的数据段,扩展成 80 个 32 位(字)的数据段(w[0]~w[79]),用于后续的 80 步压缩算法
第一步:初始化 16 个字
这 16 个字来自于 512 位的数据段,SHA-1 使用大端序,所以每个 32 位字由 4 个连续的字节构成
数据块:B0,B1,B2,B3,B4…..B63(每个 B 是一个字节)
w[0] = (B0<<24)|(B1<<16)|(B2<<8)|B3w[1] = (B4<<24)|(B5<<16)|(B6<<8)|B7- ……
w[15] = (B60<<24)|(B61<<16)|(B62<<8)|B63对于字符串"password",填充过后的 16 个字就应该是:
| |
第二步:扩展后 64 个字(w[16]~w[79])
这个是扩展的核心部分,对于 t 从 16 到 79,每一个 w[t] 都是由前面已有的 4 个值通过异或和循环左移得到的
计算公式: W[t] = ROTL^1(W[t-3] XOR W[t-8] XOR W[t-14] XOR W[t-16] )
ROTL^1(x)代表将 x 循环左移 1 位XOR:按位异或的操作 下面来手动计算几个后面的值:
计算w[16]:w[16-3]=w[13]=0x00000000w[16-8]=w[8]=0x00000000w[16-14]=w[2]=0x80000000w[16-16]=w[0]=0x70617373接着,进行异或0x00000000^0x00000000^0x80000000^0x70617373=0xF0617373
接着,循环左移 1 位,0xF0617373的二进制是:1111 0000 0110 0001 0111 0011 0111 0011,左移 1 位得到1110 0000 1100 0010 1110 0110 1110 0111
得到w[16]=0xE0C2E6E7
再来算一下w[17]w[17-3]=w[14]=0x00000000w[17-8]=w[9]=0x00000000w[17-14]=w[3]=0x00000000w[17-16]=w[1]=0x776f7264异或:0x00000000^0x00000000^0x00000000^0x776f7264=0x776f72640x776f7264=>0111 0111 0110 1111 0111 0010 0110 0100- 左移 1 位:
1110 1110 1101 1110 1110 0100 1100 1000得到w[17]=0xEEDEE4C8
最后得到的 80 个字的数据块为:
| |
初始化常量
这里与 MD5 不同的是,它有 5 个初始化常量(A,B,C,D,E),初始值为固定的魔术常量(大端序)
这些初始值将在处理完每个 512 位数据块后,与该块计算出的中间哈希值进行累加
处理分组数据
SHA1 跟 MD5 一样,都会涉及到 4 轮运算,每一轮扩展到 20 次,一共变成 80 次非线性函数的运算
首先来看一下 4 个非线性函数
| |
80 次非线性运算被均分为 4 个阶段,每 20 步为一组,每个阶段使用不同的逻辑函数 f 和常量 k
接着来到具体的运算:
((a << 5) & 0xffffffff) | (a >> 27),这个实现了 32 位循环左移 5 位
a << 5:将 a 左移 5 位,但是右边移出的位会确实,自动补 0a >> 27:将 a 右移 27 位,右移 27 位之后得到的正式原始 a 最左边的 5 位,现在位于结果的右侧了|:按位或操作,将左移的 5 位与右移的 27 位合并,效果正好是将 a 循环左移了 5 位& 0xffffffff:确保结果仍然是 32 位temp = (temp + f + e + k + w[i]) & 0xffffffff:将所有的这个玩意儿混合到了一起temp:循环左移 5 位过后的 af:上面的这个非线性函数e:之前的那个初始化常量值k:上面的常量 k 值w[i]:填充过后的数据块的值
算出来的值按照这样的规则进行交换
如下图所示: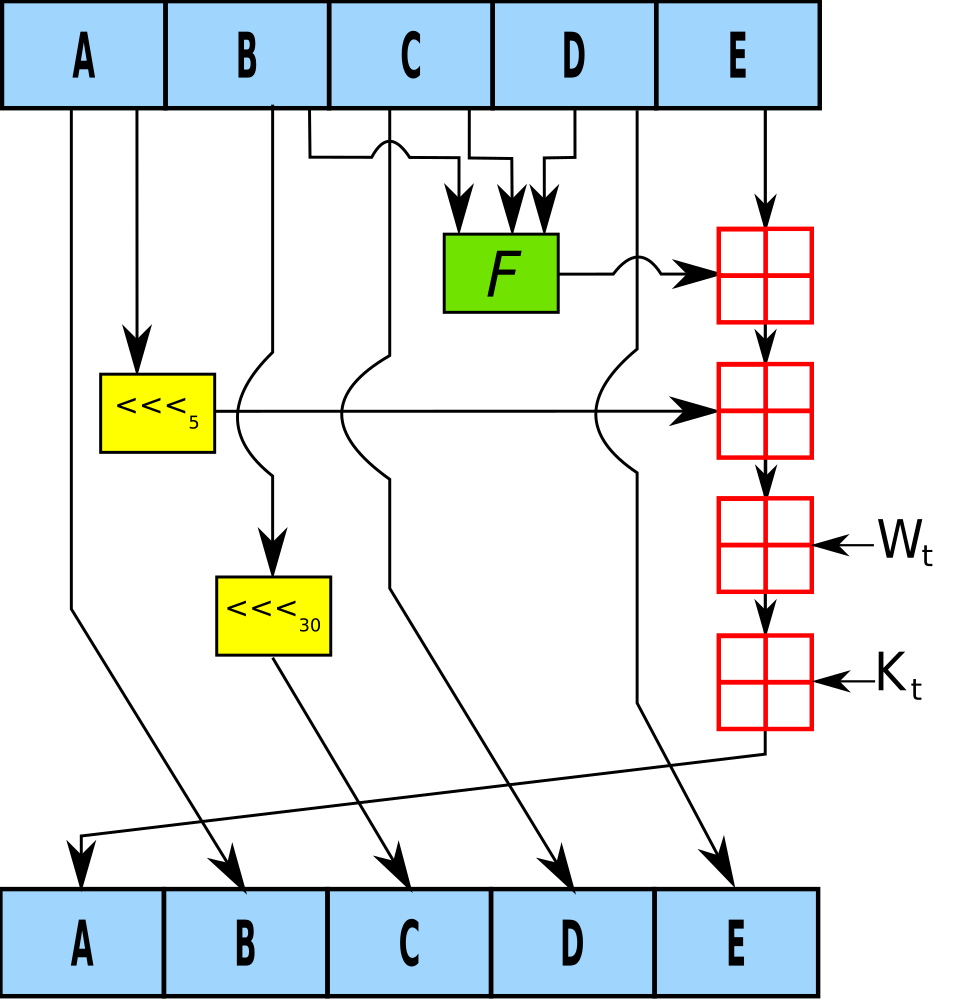
运算之后,a,b,c,d,e 值获得了更新,然后相加赋值给了 A,B,C,D,E,最后拼接起来,就得到了最终的值
python 代码
| |
常见的魔改点
- 初始化常量
- 非线性函数逻辑
- k 值
- ……